Job Sequencing Problem with Integer Lengths
Here we show how to solve job sequencing problems with integer lengths using JijZept and JijModeling. This problem is also described in 6.3. Job Sequencing with Integer Lengths on Lucas, 2014, "Ising formulations of many NP problems".
What is Job Sequencing Problem with Integer Lengths?
We consider several tasks with integer lengths (i.e., task 1 takes one hour to execute on a computer, task 2 takes three hours, and so on). We ask: when distributing these tasks to multiple computers, what combinations can be the optimal solution to distribute these computers' execution time without creating bias?
Example
Let's take a look at the following situation.
Here are 10 tasks and 3 computers. The length of each of the 10 tasks is 1, 2, ..., 10. Our goal is to assign these tasks to the computers and minimize the maximum amount of time the tasks take. In this case, the optimal solution is and , whose maximum of execution time of computers is 19.
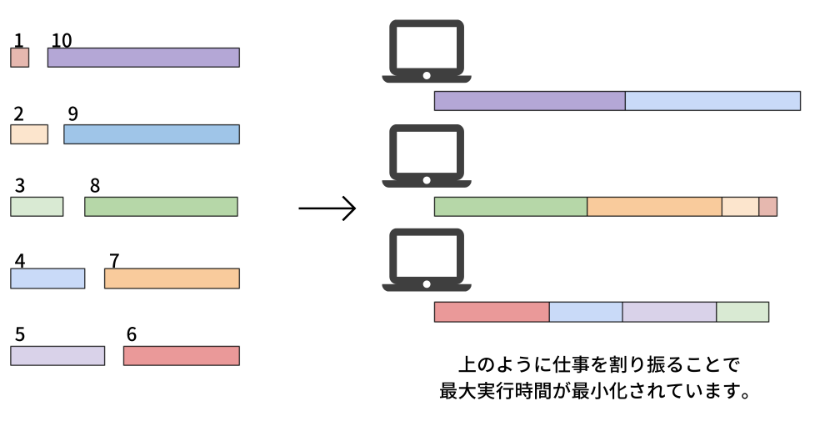
Generalization
Next, we introcude tasks and list of the execution time . Given computers, the total execution time of -th computer to perform its assigned tasks is where is a set of assigned tasks to -th computer. Finally, let us denote to be a binary variable which is 1 if -th task is assigned to -th computer, and 0 otherwise.
Constraint: each task must be assigned to one computer
For instance, it is forbidden to assign the 5th task to the 1st and 2nd computers simultaneously. We express this constraint as follows:
Objective function: minimize the difference between the execution time of the 0th computer and others
We consider the execution time of the 0th computer as the reference and minimize the difference between it and others. This reduces the execution time variability and tasks are distributed equally.
Modeling by JijModeling
Next, we show an implementation using JijModeling. We first define variables for the mathematical model described above.
import jijmodeling as jm
# defin variables
L = jm.Placeholder('L', ndim=1)
N = L.len_at(0, latex="N")
M = jm.Placeholder('M')
x = jm.BinaryVar('x', shape=(N, M))
i = jm.Element('i', belong_to=(0, N))
j = jm.Element('j', belong_to=(0, M))
L is a one-dimensional array representing the execution time of each task.
N denotes the number of tasks.
M is the number of computers.
Then, we define a two-dimensional list of binary variables x.
Finally, we set the subscripts i and j used in the mathematical model.
Constraint
We implement a constraint Equation (1).
# set problem
problem = jm.Problem('Integer Jobs')
# set constraint: job must be executed using a certain node
problem += jm.Constraint('onehot', x[i, :].sum()==1, forall=i)
x[i, :].sum() is syntactic sugar of sum(j, x[i, j]).
Objective function
Next, we implement an objective function Equation (2).
# set objective function: minimize difference between node 0 and others
A_0 = jm.sum(i, L[i]*x[i, 0])
A_j = jm.sum(i, L[i]*x[i, j])
problem += jm.sum((j, j!=0), (A_0 - A_j) ** 2)
sum((j, j!=0), ...) denotes taking the sum of all cases where j is not 0.
Let's display the implemented mathematical model in Jupyter Notebook.
problem
Prepare an instance
We set the execution time of each job and the number of computers. At this time, we use the same values from an example as we describe before.
# set a list of jobs
inst_L = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# set the number of Nodes
inst_M = 3
instance_data = {'L': inst_L, 'M': inst_M}
Solve by JijZept's SA
We solve this problem using JijZept JijSASampler. We also use the parameter search function by setting search=True.
import jijzept as jz
# set sampler
config_path = "config.toml"
sampler = jz.JijSASampler(config=config_path)
# solve problem
response = sampler.sample_model(problem, instance_data, multipliers={"onehot": 0.5}, num_reads=100, search=True)
Visualize the solution
In the end, we extract the lowest energy solution from the feasible solutions and visualize it.
import matplotlib.pyplot as plt
import numpy as np
# get samplset which is returned from JijZept
sampleset = response.get_sampleset()
# extract feasible samples
feasible_samples = sampleset.feasibles()
# get the values of feasible objective function
feasible_objectives = [sample.eval.objective for sample in feasible_samples]
if len(feasible_objectives) == 0:
print('No feasible solution found ...')
else:
# get the lowest index of value of feasible objective function
lowest_index = np.argmin(feasible_objectives)
# get the solution of the lowest index
x_indices = feasible_samples[lowest_index].var_values["x"].values
# get the instance information
L = instance_data["L"]
M = instance_data["M"]
# initialize execution time
exec_time = np.zeros(M, dtype=np.int64)
# compute summation of execution time each nodes
for i, j in x_indices:
plt.barh(j, L[i], left=exec_time[j],ec="k", linewidth=1,alpha=0.8)
plt.text(exec_time[j] + L[i] / 2.0 - 0.25 ,j-0.05, str(i+1),fontsize=12)
exec_time[j] += L[i]
plt.yticks(range(M))
plt.ylabel('Computer numbers')
plt.xlabel('Execution time')
plt.show()
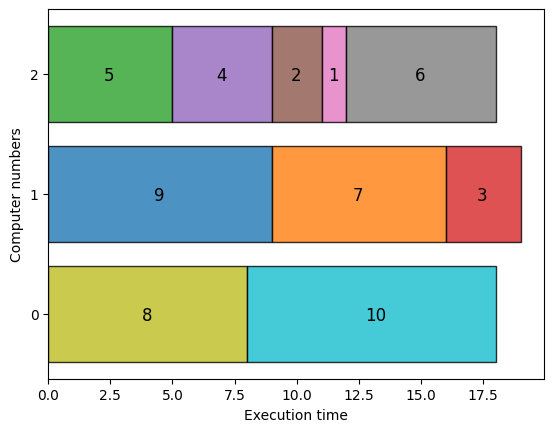
With the above visualization, we obtain a graph where the execution times of three computers are approximately equal. The maximum execution time is still 19, so this is optimal solution.